Publikus bétában a Google Spanner
2017. február 15.
 Adattárházak · BigData · Google
Adattárházak · BigData · Google
A Google a nagy nyilvánosság számára is elérhetővé tette globális méretekben is skálázható tranzakciós adatbázisát.
A Google Spanner kiemelkedő jellemzője, hogy úgy nyújt valódi tranzakciókezelést, hogy közben sem a nagyfokú skálázhatóságot, sem a hibatűrést nem áldozza fel.
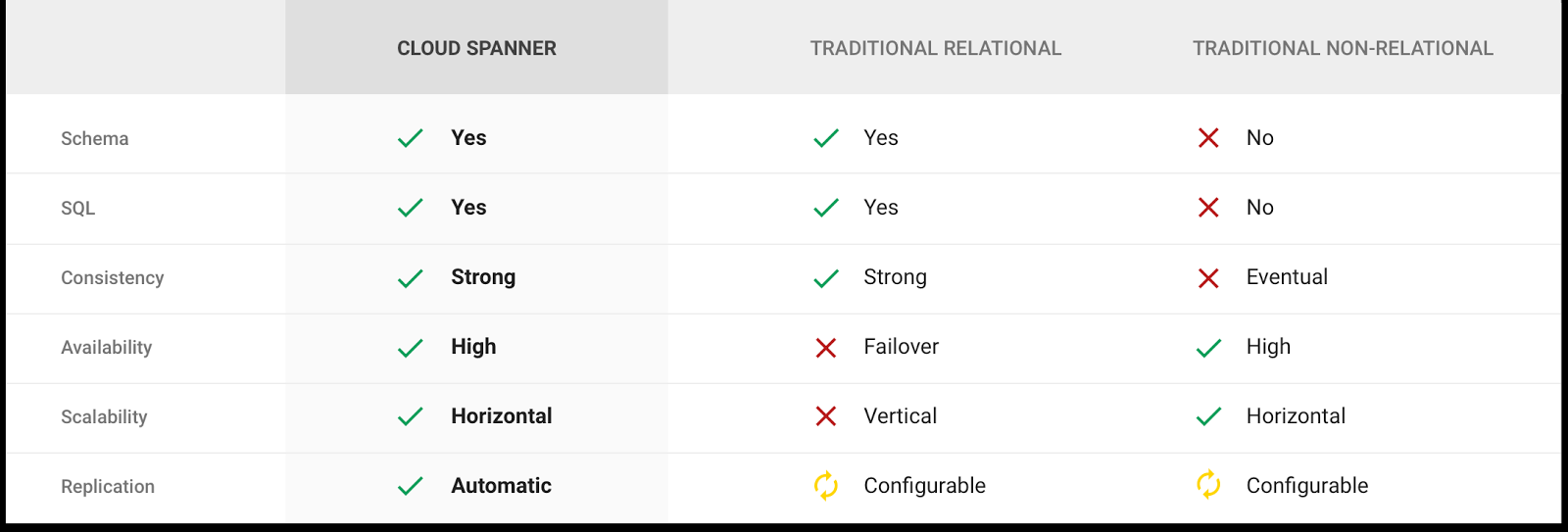 A Spanner összehasonlítása a hagyományos SQL és NOSQL technológiákkal A Spanner összehasonlítása a hagyományos SQL és NOSQL technológiákkal
Az elosztott adatbázisok működését leíró CAP elmélet szerint a Consisteny (konszisztencia), Availability (elérhetőség), Partition tolerance (kb. particióvesztés-állóság) hármasából egyszerre csak kettő érhető el. Ezért olyan adatbázist készíteni szinte lehetetlen, ami konzisztensen kezeli a tranzakciókat, tetszés szerint skálázható akárhány gépre, és közben bármikor elérhető.
A Spanner ezt az ellentmondást úgy oldja fel, hogy teljes egészében a Google által működtetett belső, redundáns hálózati infrastruktúrán fut. Ennek következtében a hálózati szakadásokból származó problémák nagyon-nagyon ritkák, a Google szerint a rendelkezésre állás 5 kilences nagyságrendű. Így szigorúan véve a Spanner a CP kategóriába tartozik (konzisztens és particióvesztés-tűrő), egy kiemelkedően magas, bár nem 100%-os elérhetőség mellett.
A Spanner működéséről érdekes részlettel szolgál a Quizlet blogja is, akik korai felhasználóként alapos és részletes teszteket futtattak.
A Google a Spannert már közel tív éve fejleszti, az első nyilvános technikai leírás 2012-ben jelent meg. Most közzétettek egy új tanulmányt is, amely többek között a particiószakadás kezelésével foglalkozik. A cég legkritikusabb üzleti alkalmazásai mára a Spanneren futnak, ideértve az Adwords és a Google Play szolgáltatásokat.
A Google Cloudon futó Spanner saját oldala itt érhető el, az árazásról pedig itt lehet tájékozódni.
|


